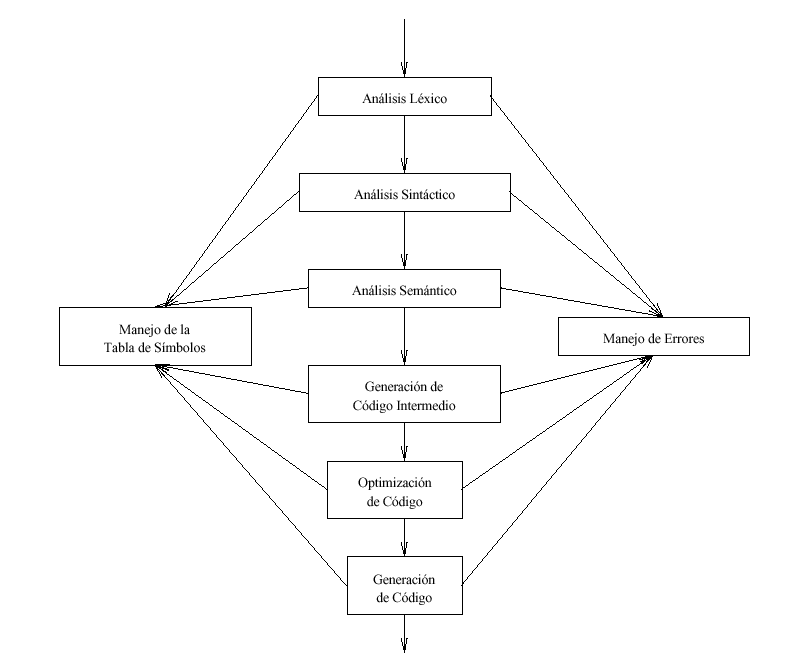
Conceptualmente un compilador opera en fases. Cada una de las cuales transforma el programa fuente de una representación en otra. En la figura 3 se muestra una descomposición típica de un compilador. En la práctica se pueden agripar fases y las representaciones intermedias entres las fases agrupadas no necesitan ser construidas explícitamente.
Programa fuente
Programa objeto
Figura 3.- Fases de un compilador.
Las tres primeras fases, que forman la mayor parte de la porción de análisis de un compilador se analizan en la sección IX. Otras dos actividades, la administración de la tabla se símbolos y el manejo de errores, se muestran en interacción con las seis fases de análisis léxico, análisis sintáctico, análisis semántico, generación de código intermedio, optimación de código y generación de código. De modo informal, también se llamarán "fases" al administrador de la tabla de símbolos y al manejador de errores.
Figura 3.- Fases de un compilador.
Las tres primeras fases, que forman la mayor parte de la porción de análisis de un compilador se analizan en la sección IX. Otras dos actividades, la administración de la tabla se símbolos y el manejo de errores, se muestran en interacción con las seis fases de análisis léxico, análisis sintáctico, análisis semántico, generación de código intermedio, optimación de código y generación de código. De modo informal, también se llamarán "fases" al administrador de la tabla de símbolos y al manejador de errores.
Administrador de la tabla de símbolos
Una función esencial de un compilador es registrar los identificadores utilizados en el programa fuente y reunir información sobre los distintos atributos de cada identificador. Estos atributos pueden proporcionar información sobre la memoria asignada a un identificador, su tipo, su ámbito (la parte del programa donde tiene validez) y, en el caso de nombres de procedimientos, cosas como el número y tipos de sus argumentos, el método de pasar cada argumento (por ejemplo, por referencia) y el tipo que devuelve, si los hay.
Una tabla de símbolos es una estructura de datos que contiene un registro por cada identificador, con los campos para los atributos del identificador. La estructura de datos permite encontrar rápidamente el registro de cada identificador y almacenar o consultar rápidamente datos en un registro
Cuando el analizador léxico detecta un indentificador en el programa fuente, el identificador se introduce en la tabla de símbolos. Sin embargo, normalmente los atributos de un identificador no se pueden determinar durante el análisis léxico. Por ejemplo, en una declaración en Pascal como var posición, inicial, velocidad : real;
El tipo real no se conoce cuando el analizador léxico encuentra posición, inicial y velocidad.
Las fases restantes introducen información sobre los identificadores en la tabla de símbolos y después la utilizan de varias formas. Por ejemplo, cuando se está haciendo el análisis semántico y la generación de código intermedio, se necesita saber cuáles son los tipos de los identificadores, para poder comprobar si el programa fuente los usa de una forma válida y así poder generar las operaciones apropiadas con ellos. El generador de código, por lo general, introduce y utiliza información detallada sobre la memoria asignada a los identificadores.
Una función esencial de un compilador es registrar los identificadores utilizados en el programa fuente y reunir información sobre los distintos atributos de cada identificador. Estos atributos pueden proporcionar información sobre la memoria asignada a un identificador, su tipo, su ámbito (la parte del programa donde tiene validez) y, en el caso de nombres de procedimientos, cosas como el número y tipos de sus argumentos, el método de pasar cada argumento (por ejemplo, por referencia) y el tipo que devuelve, si los hay.
Una tabla de símbolos es una estructura de datos que contiene un registro por cada identificador, con los campos para los atributos del identificador. La estructura de datos permite encontrar rápidamente el registro de cada identificador y almacenar o consultar rápidamente datos en un registro
Cuando el analizador léxico detecta un indentificador en el programa fuente, el identificador se introduce en la tabla de símbolos. Sin embargo, normalmente los atributos de un identificador no se pueden determinar durante el análisis léxico. Por ejemplo, en una declaración en Pascal como var posición, inicial, velocidad : real;
El tipo real no se conoce cuando el analizador léxico encuentra posición, inicial y velocidad.
Las fases restantes introducen información sobre los identificadores en la tabla de símbolos y después la utilizan de varias formas. Por ejemplo, cuando se está haciendo el análisis semántico y la generación de código intermedio, se necesita saber cuáles son los tipos de los identificadores, para poder comprobar si el programa fuente los usa de una forma válida y así poder generar las operaciones apropiadas con ellos. El generador de código, por lo general, introduce y utiliza información detallada sobre la memoria asignada a los identificadores.
Detección e información de errores
Cada frase puede encontrar errores. Sin embargo, después de detectar un error. Cada fase debe tratar de alguna forma ese error, para poder continuar la compilación, permitiendo la detección de más errores en el programa fuente. Un compilador que se detiene cuando encuentra el primer error, no resulta tan útil como debiera.
Las fases de análisis sintáctico y semántico por lo general manejan una gran proporción de los errores detectables por el compilador. La fase léxica puede detectar errores donde los caracteres restantes de la entrada no forman ningún componente léxico del lenguaje. Los errores donde la cadena de componentes léxicos violan las reglas de estructura (sintaxis) del lenguaje son determinados por la fase del análisis sintáctico.
Durante el análisis semántico el compilador intenta detectar construcciones que tengan la estructura sintáctica correcta, pero que no tengan significado para la operación implicada, por ejemplo, si se intenta sumar dos identificadores. Uno de los cuales es el nombre de una matriz, y el otro, el nombre de un procedimiento.
Cada frase puede encontrar errores. Sin embargo, después de detectar un error. Cada fase debe tratar de alguna forma ese error, para poder continuar la compilación, permitiendo la detección de más errores en el programa fuente. Un compilador que se detiene cuando encuentra el primer error, no resulta tan útil como debiera.
Las fases de análisis sintáctico y semántico por lo general manejan una gran proporción de los errores detectables por el compilador. La fase léxica puede detectar errores donde los caracteres restantes de la entrada no forman ningún componente léxico del lenguaje. Los errores donde la cadena de componentes léxicos violan las reglas de estructura (sintaxis) del lenguaje son determinados por la fase del análisis sintáctico.
Durante el análisis semántico el compilador intenta detectar construcciones que tengan la estructura sintáctica correcta, pero que no tengan significado para la operación implicada, por ejemplo, si se intenta sumar dos identificadores. Uno de los cuales es el nombre de una matriz, y el otro, el nombre de un procedimiento.
Las fases de análisis
Conforme avanza la traducción, la representación interna del programa fuente que tiene el compilador se modifica. Para ilustrar esas representaciones, considérese la traducción de la proposición
Posición := inicial + velocidad * 60 (1)
La figura 4 muestra la representación de esa proposición después de cada frase.
Posición := inicial + velocidad * 60
Id1 := id2 + id3 * 60
Tabla de símbolos
1
2
3
4 : =
id1 +
id2 *
id3 entareal
60
temp1 := entareal(60)
temp2 := id3 * temp1
temp3 := id2 + temp2
id1 := temp3
temp1 := id3 * 60.0
id1 := id2 + temp1
MOVF id3, R2
MULF #60.0, R2
MOVF id2, R1
ADDF R2, R1
MOVF R1, id1
Conforme avanza la traducción, la representación interna del programa fuente que tiene el compilador se modifica. Para ilustrar esas representaciones, considérese la traducción de la proposición
Posición := inicial + velocidad * 60 (1)
La figura 4 muestra la representación de esa proposición después de cada frase.
Posición := inicial + velocidad * 60
Id1 := id2 + id3 * 60
Tabla de símbolos
1
2
3
4 : =
id1 +
id2 *
id3 entareal
60
temp1 := entareal(60)
temp2 := id3 * temp1
temp3 := id2 + temp2
id1 := temp3
temp1 := id3 * 60.0
id1 := id2 + temp1
MOVF id3, R2
MULF #60.0, R2
MOVF id2, R1
ADDF R2, R1
MOVF R1, id1
Figura 4.- Representación de una proposición.
La fase de análisis léxico lee los caracteres de un programa fuente y los agrupa en una cadena de componentes léxicos en los que cada componente representa una secuencia lógicamente coherente de caracteres, como un identificador, una palabra clave (if, while, etc), un carácter de puntuación, o un operador de varios caracteres, como :=. La secuencia de caracteres que forman un componente léxico se denomina lexema del componente.
A ciertos componentes léxicos se les agregará un "valor léxico". Así, cuando se encuentra un identificador como velocidad, el analizador léxico no sólo genera un componente léxico, por ejemplo, id, sino que también introduce el lexema velocidad en la tabla de símbolos, si aún no estaba allí. El valor léxico asociado con esta aparición de id señala la entrada de la tabla de símbolos correspondiente a velocidad.
Usaremos id1 , id2 e id3 para posición, inicial y velocidad, respectivamente, para enfatizar que la representación interna de un identificador es diferente de la secuencia de caracteres que forman el identificador. Por tanto, la representación de (1) después del análisis léxico queda sugerida por:
id1 := id2 + id3 * 60 (2)
La fase de análisis léxico lee los caracteres de un programa fuente y los agrupa en una cadena de componentes léxicos en los que cada componente representa una secuencia lógicamente coherente de caracteres, como un identificador, una palabra clave (if, while, etc), un carácter de puntuación, o un operador de varios caracteres, como :=. La secuencia de caracteres que forman un componente léxico se denomina lexema del componente.
A ciertos componentes léxicos se les agregará un "valor léxico". Así, cuando se encuentra un identificador como velocidad, el analizador léxico no sólo genera un componente léxico, por ejemplo, id, sino que también introduce el lexema velocidad en la tabla de símbolos, si aún no estaba allí. El valor léxico asociado con esta aparición de id señala la entrada de la tabla de símbolos correspondiente a velocidad.
Usaremos id1 , id2 e id3 para posición, inicial y velocidad, respectivamente, para enfatizar que la representación interna de un identificador es diferente de la secuencia de caracteres que forman el identificador. Por tanto, la representación de (1) después del análisis léxico queda sugerida por:
id1 := id2 + id3 * 60 (2)
Se deberían construir componentes para el operador de varios caracteres := y el número 60, para reflejar su representación interna. En la sección IX ya se introdujeron las fases segunda y tercera: los análisis sintáctico y semántico. El análisis sintáctico impone una estructura jerárquica a la cadena de componentes léxicos, que se representará por medio de árboles sintácticos, como se muestra en la figura 5A). Una estructura de datos típica para el árbol se muestra en la figura 5B), en la que un nodo interior es un registro con un campo para el operador y dos campos que contienen apuntadores a los registros de los hijos izquierdo y derecho. Una hoja es un registro con dos o más campos, uno para identificar el componente léxico de la hoja, y los otros para registrar información sobre el componente léxico. Se puede tener información adicional sobre las construcciones del lenguaje añadiendo más campos a les registros de los nodos.
: =
id1 +
id2 *
id360
(a)
: =
id1 +
id2 *
id360
(a)
:= ¦ ç ¦ ç
|
id ¦ 1
|
+ ¦ ç ¦ ç
|
id ¦ 1
|
* ¦ ç ¦ ç
|
id ¦ 3
|
num¦60
|
(b)
Figura 5.- La estructura de datos en (b) corresponde al árbol en (a).
Generación de código intermedio
Después de los análisis sintáctico y semántico, algunos compiladores generan una representación intermedia explícita del programa fuente. Se puede considerar esta representación intermedia como un programa para una máquina abstracta. Esta representación intermedia debe tener dos propiedades importantes; debe ser fácil de producir y fácil de traducir al programa objeto.
La representación intermedia puede tener diversas formas. Existe una forma intermedia llamada "código de tres direcciones", que es como el lenguaje ensamblador para una máquina en la que cada posición de memoria puede actuar como un registro. El código de tres direcciones consiste en una secuencia de instrucciones, cada una de las cuales tiene como máximo tres operandos. El programa fuente de (1) puede aparecer en código de tres direcciones como
temp1 := entarea1(60)
temp2 := id3 * temp1 (2)
temp3 := id2 + temp2
id1 := temp3
Después de los análisis sintáctico y semántico, algunos compiladores generan una representación intermedia explícita del programa fuente. Se puede considerar esta representación intermedia como un programa para una máquina abstracta. Esta representación intermedia debe tener dos propiedades importantes; debe ser fácil de producir y fácil de traducir al programa objeto.
La representación intermedia puede tener diversas formas. Existe una forma intermedia llamada "código de tres direcciones", que es como el lenguaje ensamblador para una máquina en la que cada posición de memoria puede actuar como un registro. El código de tres direcciones consiste en una secuencia de instrucciones, cada una de las cuales tiene como máximo tres operandos. El programa fuente de (1) puede aparecer en código de tres direcciones como
temp1 := entarea1(60)
temp2 := id3 * temp1 (2)
temp3 := id2 + temp2
id1 := temp3
Esta representación intermedia tiene varias propiedades. Primera, cada instrucción de tres direcciones tiene a lo sumo un operador, además de la asignación. Por tanto, cuando se generan esas instrucciones el compilador tiene que decidir el orden en que deben efectuarse, las operaciones; la multiplicación precede a la adición al programa fuente de (1).
Segunda, el compilador debe generar un nombre temporal para guardar los valores calculados por cada instrucción. Tercera, algunas instrucciones de "tres direcciones" tienen menos de tres operadores, por ejemplo la primera y la última instrucciones de (2).
Segunda, el compilador debe generar un nombre temporal para guardar los valores calculados por cada instrucción. Tercera, algunas instrucciones de "tres direcciones" tienen menos de tres operadores, por ejemplo la primera y la última instrucciones de (2).
Optimación de Código
La fase de optimación de código trata de mejorar el código intermedio de modo que resulte un código de máquina más rápido de ejecutar. Algunas optimaciones son triviales. Por ejemplo, un algoritmo natural genera el código intermedio (2) utilizando una instrucción para cada operador de la representación del árbol después del análisis semántico, aunque hay una forma mejor de realizar los mismos cálculos usando las dos instrucciones
Temp1 := id3 * 60.0 (3)
Id1 := id2 + temp1
Este sencillo algoritmo no tiene nada de malo, puesto que el problema se puede solucionar en la fase de optimación de código. Esto es, el compilador puede deducir que la conversión de 60 de entero a real se puede hacer de una vez por todas en el momento de la compilación, de modo que la operación entreal se puede eliminar. Además, temp3 se usa sólo una vez, para transmitir su valor a id1. Entonces resulta seguro sustituir a id1 por temp3, a partir de lo cual la última proposición de (2) no se necesita y se obtiene el código de (3).
Hay muchas variaciones en la cantidad de optimación de código que ejecutan los distintos compiladores. En lo que hacen mucha optimación llamados "compiladores optimadores", una parte significativa del tiempo del compilador se ocupa en esta fase. Sin embargo hay optimaciones sencillas que mejoran significativamente del tiempo del compilador se ocupa en esta fase. Sin embargo, hay optimaciones sencillas que mejoran sensiblemente el tiempo de ejecución del programa objeto sin retardar demasiado la compilación.
La fase de optimación de código trata de mejorar el código intermedio de modo que resulte un código de máquina más rápido de ejecutar. Algunas optimaciones son triviales. Por ejemplo, un algoritmo natural genera el código intermedio (2) utilizando una instrucción para cada operador de la representación del árbol después del análisis semántico, aunque hay una forma mejor de realizar los mismos cálculos usando las dos instrucciones
Temp1 := id3 * 60.0 (3)
Id1 := id2 + temp1
Este sencillo algoritmo no tiene nada de malo, puesto que el problema se puede solucionar en la fase de optimación de código. Esto es, el compilador puede deducir que la conversión de 60 de entero a real se puede hacer de una vez por todas en el momento de la compilación, de modo que la operación entreal se puede eliminar. Además, temp3 se usa sólo una vez, para transmitir su valor a id1. Entonces resulta seguro sustituir a id1 por temp3, a partir de lo cual la última proposición de (2) no se necesita y se obtiene el código de (3).
Hay muchas variaciones en la cantidad de optimación de código que ejecutan los distintos compiladores. En lo que hacen mucha optimación llamados "compiladores optimadores", una parte significativa del tiempo del compilador se ocupa en esta fase. Sin embargo hay optimaciones sencillas que mejoran significativamente del tiempo del compilador se ocupa en esta fase. Sin embargo, hay optimaciones sencillas que mejoran sensiblemente el tiempo de ejecución del programa objeto sin retardar demasiado la compilación.
No hay comentarios:
Publicar un comentario